⚠️ AWS Outage Deep Dive: 58 Services Impacted in US-EAST-1 Region — Root Cause Identified as DNS Resolution Issue
Date: October 20, 2025
Region Affected: N. Virginia (US-EAST-1)
Status: 🔴 Disrupted
Severity: High Impact
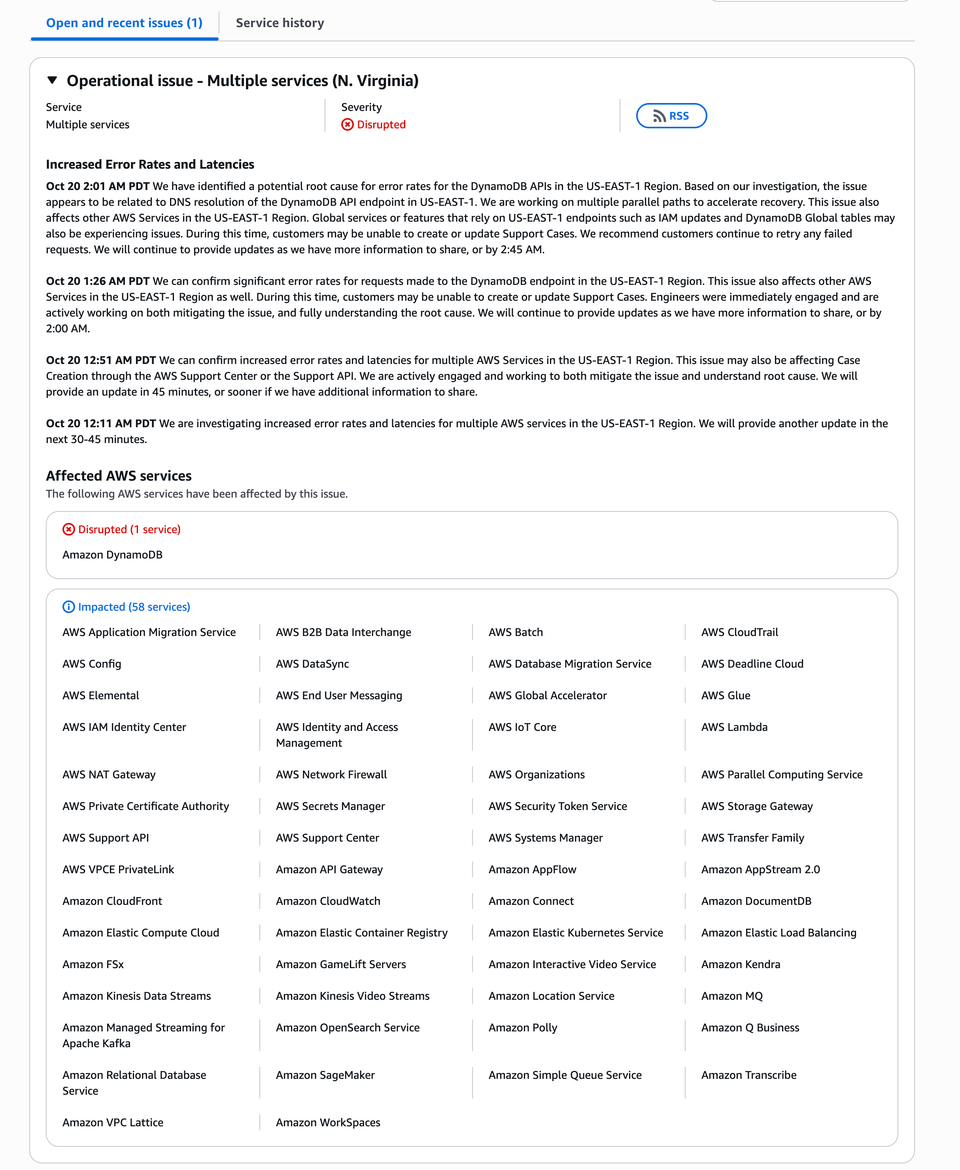
Amazon Web Services (AWS) — the backbone of global cloud infrastructure — is currently battling a major disruption in its US-EAST-1 (N. Virginia) region, one of its largest and most mission-critical data centers.
As of 2:01 AM PDT, AWS engineers have identified a potential root cause related to DNS resolution issues affecting the DynamoDB API endpoint, which has now triggered cascading latency and availability problems across 58 AWS services.
🧩 The Situation So Far
AWS first reported increased error rates and latencies around 12:11 AM PDT, escalating the issue to a full “Disrupted” state by 12:26 AM PDT when Amazon DynamoDB began showing critical service degradation.
Subsequent updates revealed that dependent systems — including EC2, CloudWatch, IAM, Lambda, and CloudFront — were also affected.
At 2:01 AM PDT, AWS confirmed they had isolated a potential root cause:
“The issue appears to be related to DNS resolution of the DynamoDB API endpoint in US-EAST-1. We are working on multiple parallel paths to accelerate recovery. This issue also affects other AWS services in the US-EAST-1 region. Global features that rely on US-EAST-1 endpoints, such as IAM updates and DynamoDB Global Tables, may also be impacted.”
🧠 Root Cause: DNS Resolution Failure
This particular incident is significant because DNS (Domain Name System) failures in AWS environments can propagate through multiple services simultaneously.
When a core API — such as DynamoDB’s endpoint — experiences DNS lookup issues, dependent systems that rely on internal DNS for service discovery can fail to connect.
In this case, the DNS resolution issue disrupted:
- API requests to DynamoDB, causing failed reads/writes
- IAM propagation between regions (due to dependency on US-EAST-1 endpoints)
- CloudWatch and CloudFront metrics that rely on regional data synchronization
- Global services like Route 53 Health Checks, which use US-EAST-1 for coordination
The cascading effect underscores how deeply interwoven AWS’s internal systems are — and why a single DNS fault can have multi-layered global impact.
⚙️ Affected AWS Services (as of 2:01 AM PDT)
🔴 Disrupted
- Amazon DynamoDB — Primary database service facing significant API failures, high error rates, and write delays.
🟡 Impacted (58 Services)
🔸 Core Infrastructure & Management
- AWS Config
- AWS Systems Manager
- AWS Identity and Access Management (IAM)
- AWS IAM Identity Center
- AWS Private Certificate Authority
- AWS Security Token Service (STS)
- AWS Network Firewall
- AWS Organizations
- AWS VPCE PrivateLink
- AWS Support API / Support Center
🔸 Compute & Containers
- Amazon Elastic Compute Cloud (EC2)
- AWS Lambda
- Amazon Elastic Kubernetes Service (EKS)
- Amazon Elastic Container Registry (ECR)
- AWS Batch
- AWS Parallel Computing Service
🔸 Networking & CDN
- Amazon CloudFront
- Amazon API Gateway
- AWS NAT Gateway
- AWS Elastic Load Balancing (ELB)
- Amazon VPC Lattice
🔸 Storage & Databases
- Amazon FSx
- Amazon Relational Database Service (RDS)
- Amazon DocumentDB
- Amazon Kinesis Data Streams / Video Streams
- Amazon OpenSearch Service
- AWS DataSync
🔸 Messaging, Streaming & Integration
- Amazon MQ
- Amazon Managed Streaming for Apache Kafka
- Amazon AppFlow
- Amazon Simple Queue Service (SQS)
- AWS Transfer Family
🔸 Machine Learning & AI
- Amazon SageMaker
- Amazon Polly
- Amazon Transcribe
- AWS Glue
- Amazon Kendra
🔸 Developer Tools & Application Integration
- AWS CodeBuild
- Amazon GameLift Servers
- Amazon Connect
- Amazon WorkSpaces
- AWS Elemental
🔸 Monitoring & Observability
- Amazon CloudWatch
- AWS CloudTrail
🔸 Business Applications
- Amazon Q Business
- AWS End User Messaging
- AWS B2B Data Interchange
- Amazon Location Service
🔍 How It Spreads: The Chain Reaction Inside AWS
The US-EAST-1 region is not only AWS’s first data center but also the control hub for many global operations.
Several global services, including IAM, STS, and CloudFormation, have dependencies in US-EAST-1 even when used elsewhere.
When the DynamoDB endpoint started failing due to DNS issues:
- AWS SDKs and CLI tools began timing out.
- Monitoring tools (CloudWatch, Grafana integrations) lost data feeds.
- Serverless workloads (Lambda + API Gateway) became unresponsive.
- Customer Support Center was partially unavailable, preventing ticket submissions.
- CI/CD pipelines dependent on US-EAST-1 APIs stalled.
This demonstrates how centralized dependencies — even in a multi-region environment — can cause system-wide degradation.
🌎 Global Ripple Effects
While the issue is localized to N. Virginia, several global AWS features have been indirectly affected:
- IAM Role Replication: Delays in propagating identity updates across regions.
- DynamoDB Global Tables: Cross-region replication failures and data lag.
- S3 Bucket Operations: Some customers reported delayed uploads or metadata updates.
- Lambda@Edge: High latency in CloudFront-integrated functions.
- AWS Route 53 Health Checks: Inconsistent response data due to partial DNS resolution.
For large enterprises using AWS as the foundation of their infrastructure, these issues can lead to application downtime, API errors, and user-facing latency spikes.
🧭 AWS Response and Recovery Plan
AWS has confirmed that:
- Engineers are actively engaged worldwide to mitigate the DNS resolution issue.
- Parallel recovery paths have been initiated to reroute affected traffic.
- Customers are advised to retry failed requests and avoid new deployments in
us-east-1. - The next major update is expected by 2:45 AM PDT.
AWS has a strong record of transparency, and after resolution, they are expected to release a detailed Post-Incident Summary (PIS) describing the root cause, timeline, and corrective actions.
📊 Lessons Learned for Cloud Engineers
This event serves as a wake-up call for developers, architects, and DevOps teams:
- Design for Failure – Always assume regional disruptions are possible.
- Implement Multi-Region Failover – Use Route 53, CloudFront, and database replication across regions.
- Use Circuit Breakers – Implement logic that gracefully degrades when a service is unavailable.
- External Monitoring – Don’t rely solely on CloudWatch. Tools like Pingdom, UptimeRobot, or Grafana Cloud can provide outside-in validation.
- Chaos Testing – Simulate outages periodically (AWS Fault Injection Simulator, Gremlin) to test system resilience.
🕐 Current Timeline Summary
| Time (PDT) | Update | Status |
|---|---|---|
| 12:11 AM | AWS begins investigation into latency | Investigating |
| 12:26 AM | DynamoDB confirmed disrupted | Disrupted |
| 12:46 AM | 37 AWS services impacted | Degraded |
| 2:01 AM | Root cause identified – DNS resolution issue | Recovery efforts in progress |
| 2:45 AM (expected) | Next update scheduled | Pending |
🧭 Conclusion
This AWS US-EAST-1 outage highlights once again that no cloud region is immune to failure, no matter how advanced the provider.
The dependency between core APIs and DNS systems creates complex failure modes that can ripple across global infrastructures in seconds.
While AWS continues to mitigate and investigate, businesses should focus on:
- Implementing multi-region architectures
- Enhancing DNS redundancy
- Preparing for incident response automation
Outages like this are rare but inevitable — resilience, not avoidance, is the true key to uptime.
📍 Official Source: AWS Health Dashboard – US-EAST-1 Incident
📘 Detailed Analysis: Dargslan Publishing AWS Outage Report
If you want to learn more about AWS infrastructure, cloud reliability, and DevOps best practices,
visit 👉 dargslan.com — your hub for deep technical learning, cloud education, and professional-level IT books.