🟢 AWS US-EAST-1 Outage – Full Recovery in Progress After DNS and EC2 Launch Issues
Date: October 20, 2025
Region Affected: N. Virginia (US-EAST-1)
Status: ⚙️ Recovery and Rate-Limited Operations
After nearly seven hours of disruption across multiple AWS services, Amazon Web Services (AWS) continues to stabilize operations in the US-EAST-1 (N. Virginia) region.
What began as a DNS resolution issue affecting the DynamoDB API endpoint cascaded into widespread latency and API failures across more than 80 AWS services, including EC2, RDS, Lambda, and CloudWatch.
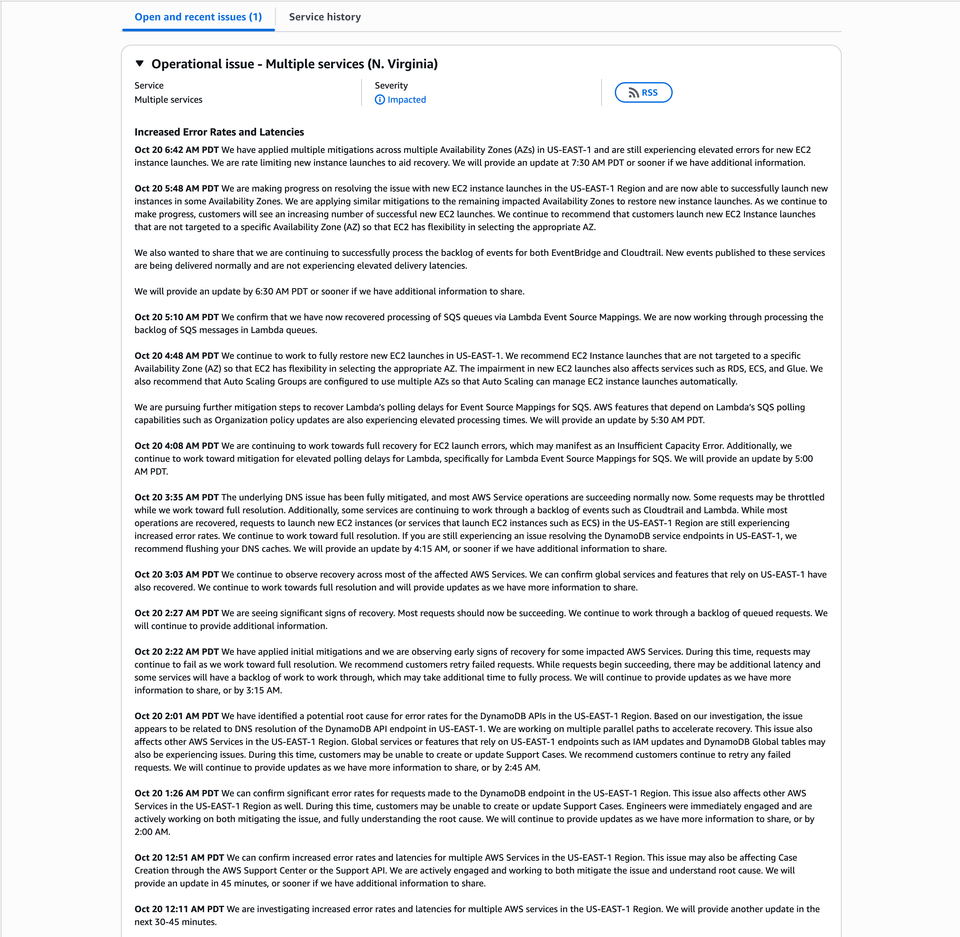
By 6:42 AM PDT, AWS confirmed that most critical systems are restored, with new EC2 instance launches still rate-limited to help manage the recovery.
🧭 Timeline of the Incident
Oct 20, 12:11 AM PDT – Initial Reports
AWS begins investigating increased error rates and latencies across multiple services in the US-EAST-1 region.
Oct 20, 12:26 AM PDT – DynamoDB Disruption Confirmed
The outage is officially attributed to DynamoDB endpoint errors due to a DNS resolution issue.
AWS engineers escalate the event to “Disrupted” severity.
Oct 20, 2:01 AM PDT – Root Cause Identified
AWS identifies the root cause as a DNS resolution failure for the DynamoDB API endpoint in US-EAST-1.
Mitigation efforts begin, affecting several dependent services such as IAM, CloudWatch, and Lambda.
Oct 20, 3:35 AM PDT – DNS Issue Fully Mitigated
AWS reports that the DNS issue has been fully mitigated and that most services are now succeeding normally.
Some EC2 launches still fail, and Lambda continues processing backlog events.
Oct 20, 4:48 AM PDT – Focus on EC2 and Lambda Recovery
AWS focuses on restoring new EC2 instance launches and Lambda SQS event processing.
Partial service recovery is confirmed for RDS, ECS, and Glue.
Oct 20, 5:10 AM PDT – Lambda Queue Recovery
AWS confirms full recovery of SQS polling for Lambda Event Source Mappings, with backlogged messages being processed.
Oct 20, 5:48 AM PDT – EC2 Launch Progress
AWS reports steady improvement in new EC2 launches across several Availability Zones.
Customers are advised to use non-AZ-specific EC2 launches to improve success rates.
Oct 20, 6:42 AM PDT – Ongoing EC2 Launch Recovery
AWS applies multiple mitigations across multiple Availability Zones (AZs) but notes elevated errors for new EC2 instance launches.
To control recovery flow, rate limiting is temporarily applied to EC2 provisioning.
All other major services, including CloudTrail, EventBridge, and Lambda, are operating normally.
⚙️ Official AWS Statement (Oct 20, 6:42 AM PDT)
“We have applied multiple mitigations across multiple Availability Zones (AZs) in US-EAST-1 and are still experiencing elevated errors for new EC2 instance launches.
We are rate limiting new instance launches to aid recovery.
We will provide an update at 7:30 AM PDT or sooner if we have additional information to share.”
This marks the final phase of restoration, with full EC2 functionality expected soon.
🧩 Affected AWS Services Overview
During the peak of the outage, 82 services were degraded or disrupted.
Key systems impacted included:
- Compute: EC2, ECS, EKS, Lambda
- Databases: DynamoDB, RDS, Aurora, DocumentDB
- Networking: VPC, Transit Gateway, NAT Gateway
- Security: IAM, STS, Private CA
- Data & Analytics: SageMaker, Redshift, Kinesis, Glue
- Monitoring: CloudWatch, CloudTrail
- Messaging: SQS, SNS, SES
- Storage: FSx, DataSync, Storage Gateway
- Developer Tools: CloudFormation, Systems Manager, AppFlow
Many of these services depend internally on DynamoDB and IAM — both of which rely on the same regional DNS endpoints.
When DNS resolution failed, service discovery and authentication broke across the ecosystem.
🔍 Why DNS Caused a Massive Ripple Effect
DNS (Domain Name System) is the address book of the internet, and AWS uses it internally to connect thousands of microservices.
A failure in DNS resolution means services can’t find each other, leading to:
- API timeouts
- Failed service-to-service communication
- Stuck autoscaling and provisioning requests
- Event delivery delays (CloudTrail, EventBridge)
While AWS is designed for regional fault isolation, many global AWS services still depend on US-EAST-1 endpoints for coordination — making this region a single point of dependency for the entire AWS network.
💡 AWS Recommendations to Customers
AWS provided specific operational advice to reduce ongoing impact:
- Use non-AZ-specific EC2 launches
- Allow Auto Scaling Groups to select available zones automatically.
- Flush local DNS caches
- If DynamoDB or EC2 API calls still fail, DNS cache clearing may help.
- Monitor application health
- CloudWatch and EventBridge are stable and processing new events.
- Avoid high-volume EC2 scaling events
- Rate limiting is in effect for recovery management.
📈 Recovery Status Summary (as of 6:42 AM PDT)
| Service Group | Status | Notes |
|---|---|---|
| DNS / DynamoDB | ✅ Fully Recovered | Core resolution stable |
| Lambda & SQS | ✅ Recovered | All queues processed |
| EC2 / ECS / RDS | ⚙️ Partially Impacted | New launches rate-limited |
| EventBridge / CloudTrail | ✅ Operational | Backlog cleared |
| IAM / STS / Global APIs | ✅ Normal | Full propagation restored |
🧭 What We Learned
This outage reinforces three crucial lessons for cloud architects and DevOps teams:
- Multi-Region Resilience Is Not Optional
Always deploy across multiple AWS regions to withstand single-region failures. - Monitor Dependencies
A regional DNS failure can break services that don’t appear related — implement deep dependency mapping. - Build for Degraded Mode
Applications should remain partially operational even when APIs or DNS endpoints fail temporarily.
🕐 Final Thoughts
The US-EAST-1 outage once again underscores the importance of resilient infrastructure and DNS redundancy in the cloud era.
Even industry giants like AWS are not immune to cascading effects when core systems like DNS falter.
AWS engineers have demonstrated rapid mitigation and transparent communication — a testament to their operational excellence.
However, this incident will likely prompt renewed interest in multi-region failover, external DNS redundancy, and cross-service monitoring.
📍 Source: AWS Service Health Dashboard
📘 Full coverage: Dargslan Publishing AWS Outage Report
If you want to learn more about cloud reliability, AWS architecture, and DevOps best practices,
visit 👉 dargslan.com — your trusted source for IT education, cloud insights, and infrastructure learning.