✅ AWS US-EAST-1 Outage Update: Recovery Underway After Major DNS-Related Disruption Impacting 60 Services
Date: October 20, 2025
Region: US-EAST-1 (N. Virginia)
Status: 🟠 Degraded (Recovering)
Severity: High
Amazon Web Services (AWS) reports steady progress in recovery efforts after a large-scale outage affected DynamoDB and nearly 60 AWS services in the US-EAST-1 (N. Virginia) region.
After several hours of disruption caused by a DNS resolution issue at the DynamoDB API endpoint, AWS engineers confirm that most requests are now succeeding.
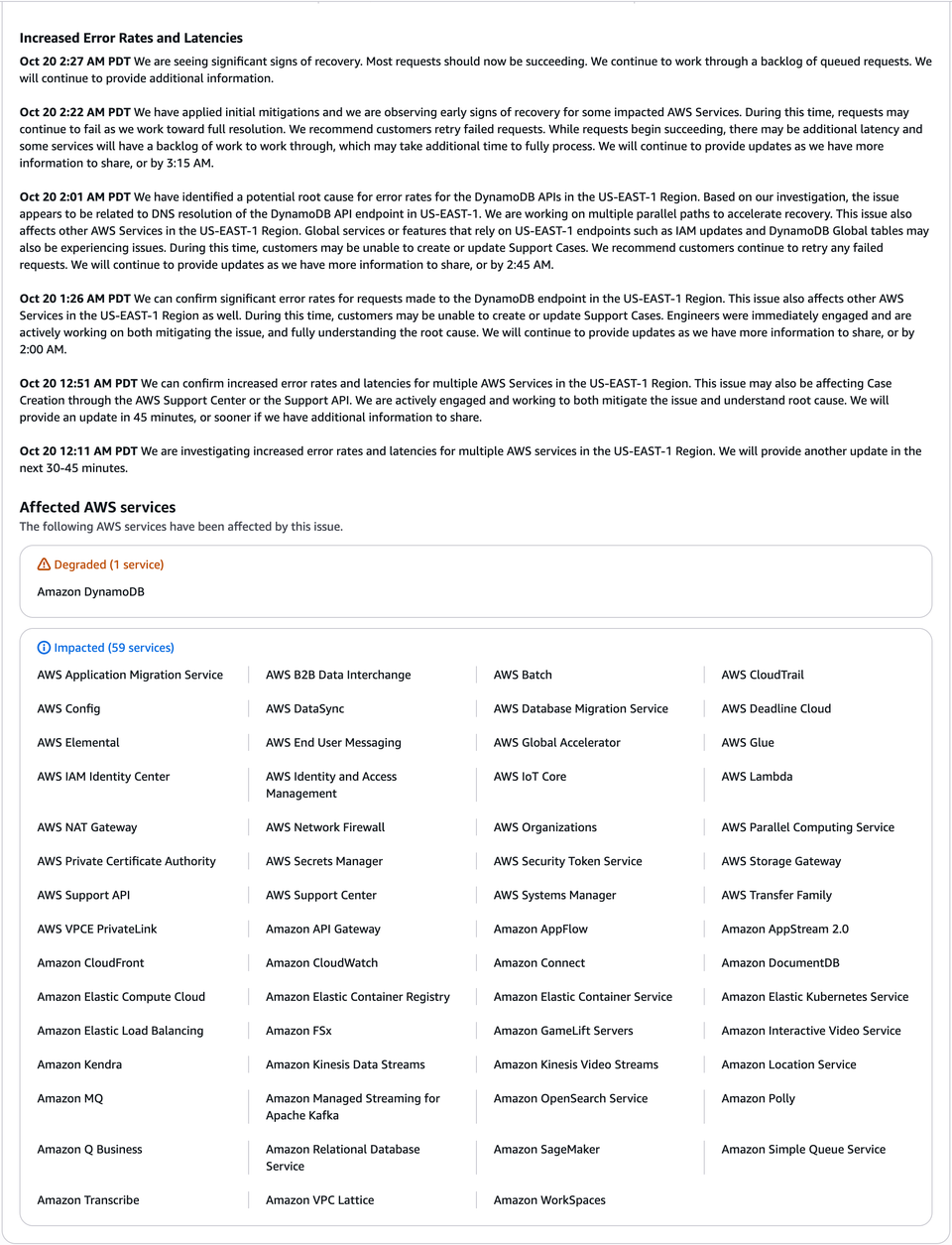
🕐 Latest Timeline (as of Oct 20, 2:27 AM PDT)
2:01 AM PDT:
“Root cause identified: DNS resolution issue for DynamoDB APIs in US-EAST-1. Parallel recovery efforts are underway. Global services relying on US-EAST-1 endpoints may experience related impact.”
2:22 AM PDT:
“We have applied initial mitigations and are observing early signs of recovery for some impacted AWS services. There may still be residual latency and queued requests while full resolution progresses.”
2:27 AM PDT:
“We are seeing significant signs of recovery. Most requests should now be succeeding. We continue to work through a backlog of queued requests.”
This confirms that AWS’s mitigation measures are effective, but some requests are still delayed as queued API calls and database writes are processed.
🧠 Root Cause Summary
AWS engineers determined that the root cause of the outage was a DNS resolution failure affecting the DynamoDB API endpoint in the N. Virginia (US-EAST-1) region.
Because this region is central to many AWS control-plane operations, the DNS issue triggered a chain reaction that impacted dozens of dependent services, including:
- Identity and Access Management (IAM)
- CloudWatch monitoring
- EC2 instance operations
- Lambda invocations
- CloudFront edge routing
- Global services such as DynamoDB Global Tables and IAM propagation
This caused API errors, latency spikes, and temporary unavailability of multiple services between 12:00 AM and 2:00 AM PDT.
⚙️ Current Service Status
🔶 Degraded (1 service)
- Amazon DynamoDB
Still processing a backlog of queued writes and reads. Most new requests are succeeding.
🟡 Impacted (59 services)
AWS reports ongoing recovery across a wide range of services including:
Core Infrastructure:
AWS Config, AWS Systems Manager, AWS IAM Identity Center, AWS Secrets Manager, AWS Private Certificate Authority, AWS Organizations, AWS Support API
Compute and Networking:
EC2, Lambda, EKS, Elastic Load Balancing, CloudFront, API Gateway, NAT Gateway, VPC Lattice, PrivateLink
Data & Storage:
DynamoDB, Amazon RDS, DocumentDB, FSx, Elastic Container Registry, OpenSearch Service, Kinesis, Kafka, DataSync
Machine Learning & AI:
Amazon SageMaker, Polly, Transcribe, Kendra, Glue
Messaging & Integration:
Amazon MQ, Simple Queue Service (SQS), AppFlow, Managed Streaming for Apache Kafka
Monitoring & Management:
CloudWatch, CloudTrail
Business & Developer Tools:
AWS Elemental, GameLift Servers, Connect, WorkSpaces, End User Messaging, B2B Data Interchange, Location Service
A full list of the 59 impacted AWS services remains available on the AWS Health Dashboard.
🌍 Regional and Global Effects
While this incident is primarily localized to the US-EAST-1 region, global ripple effects have been observed:
- IAM Role Updates: Propagation delays across regions.
- Global Tables: Cross-region replication latency in DynamoDB.
- CloudWatch Metrics: Inconsistent data delivery for applications using US-EAST-1 as their monitoring region.
- API Gateway Integrations: Temporary 5xx error rates for API calls tied to US-EAST-1 backends.
- AWS Support Portal: Limited access earlier in the incident window.
🧭 AWS Recovery Progress
AWS reports strong recovery trends, with most services returning to operational status.
Engineers are:
- Flushing queued requests from earlier connection failures.
- Validating regional endpoint DNS resolution stability.
- Monitoring residual latency on high-throughput services such as DynamoDB, CloudWatch, and Kinesis.
Full recovery is expected to take additional time, as AWS clears accumulated backlog requests and verifies consistency across dependent systems.
📊 Technical Takeaways
This event highlights the complex interdependence of AWS systems and the need for multi-region resilience even within the AWS ecosystem.
Key Lessons:
- DNS Is Critical Infrastructure: Even partial DNS resolution failures can cascade across dozens of services.
- Multi-Region Deployment: Avoid single-region dependencies for core applications.
- Retry Logic Matters: Applications should gracefully handle transient 5xx or timeout errors.
- External Monitoring: Rely on third-party uptime monitoring (e.g., Pingdom, Grafana Cloud) for faster incident detection.
- Automated Failover: Route 53 and multi-region DynamoDB tables can reduce downtime during regional disruptions.
🧭 Conclusion
The AWS US-EAST-1 outage — one of the largest in 2025 — is showing clear signs of resolution.
While DynamoDB remains degraded, most AWS customers are now experiencing restored API functionality.
The event underscores the importance of distributed architectures and resilient DNS management in modern cloud systems.
AWS is expected to release a detailed Post-Incident Summary in the coming days, outlining root cause findings and corrective measures.
📍 Official Source: AWS Health Dashboard – US-EAST-1
📘 Full Coverage: Dargslan Publishing AWS Outage Report
If you want to learn how to design resilient cloud systems, understand AWS internals, and apply DevOps best practices,
visit 👉 dargslan.com — your source for expert-level technical books, real-world tutorials, and IT mastery.