Cloudflare Global Network Outage Deepens: WARP Disabled in London as Investigation Continues
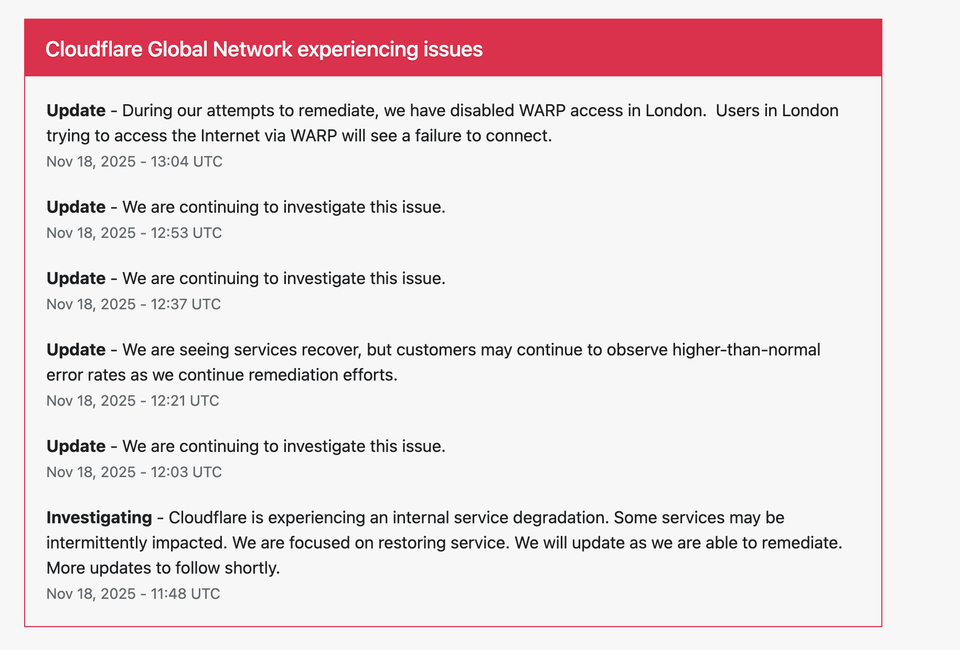
Cloudflare’s global network outage has escalated further, with the company announcing at 13:04 UTC that WARP access has been temporarily disabled in London as part of their remediation efforts. Users in London attempting to connect to the internet via Cloudflare WARP are currently unable to connect, marking a significant extension of the ongoing global disruption.
This new update adds another layer to an already widespread and complex outage that began earlier today, affecting millions of websites, APIs, applications, and Cloudflare services worldwide.
🟥 New 13:04 UTC Update: WARP Disabled in London
Cloudflare’s most recent status message states:
“During our attempts to remediate, we have disabled WARP access in London. Users in London trying to access the Internet via WARP will see a failure to connect.”
This indicates that one of Cloudflare’s key Zero Trust services—WARP, the secure VPN-like connection used by both consumers and enterprises—is now directly impacted as engineers work to stabilize the network.
Cloudflare appears to be isolating or shutting down specific regional pathways to prevent further network instability.
🕒 Full Timeline of Today’s Updates (11:48–13:04 UTC)
13:04 UTC — Update
- WARP access disabled in London
- Users in London cannot connect via WARP
- Action taken as part of remediation
12:53 UTC — Update
“We are continuing to investigate this issue.”
12:37 UTC — Update
“We are continuing to investigate this issue.”
12:21 UTC — Update
“We are seeing services recover, but customers may continue to observe higher-than-normal error rates as we continue remediation efforts.”
12:03 UTC — Update
“We are continuing to investigate this issue.”
11:48 UTC — Investigating
“Cloudflare is experiencing an internal service degradation. Some services may be intermittently impacted.”
🌍 What Services Are Affected?
The outage has reached across Cloudflare’s ecosystem, impacting:
Global Web Traffic
- Widespread 500/502/503 errors
- Slow or failed website loading
- Application and API failures
Cloudflare Dashboard
- Login issues
- Unresponsive security settings
- Incomplete or delayed analytics
Cloudflare API
- Failed calls
- Integration breakdowns
- Deployment errors
Cloudflare WARP
- Disabled in London
- Possible instability in other regions
- Connectivity failures reported
Zero Trust / Access
- Authentication and private network issues
- Delayed or unavailable access policies
Workers / Pages
- Deployment problems
- Edge execution lag
DNS & Security Layers
- Intermittent DNS resolution
- Rate-limiting, WAF or firewall delays
⚠️ Why This Outage Is Different From Typical Cloudflare Incidents
This outage stands out for multiple reasons:
1. Multiple core systems failing simultaneously
CDN, WARP, Dashboard, API, DNS, Zero Trust—all impacted at various levels.
2. Internal service degradation
Cloudflare’s own message mentions “internal degradation,” implying the root cause lies within their infrastructure rather than external routing providers.
3. Regional shutdowns (e.g., WARP London)
Disabling services regionally is unusual and indicates that isolating parts of the network is necessary to protect overall stability.
4. Long investigation window
Cloudflare has issued 5+ updates over several hours without identifying a root cause.
🔍 Possible Root Causes (Speculative but Technically Informed)
Based on the pattern of failures, the outage may stem from one of the following:
1. A flawed global configuration rollout
A problematic deployment to routing, WAF, proxies, or edge logic can crash multiple PoPs instantly.
2. Internal microservice or orchestration failure
If internal APIs, service registries, caching layers, or routing orchestrators malfunction, the entire platform becomes unstable.
3. Anycast/BGP routing instability
A misconfiguration in BGP announcements may force Cloudflare to reroute or disable regional systems (e.g., WARP in London).
4. Cascading system overload
A failure in one subsystem may create chain reactions across the network.
Until Cloudflare publishes an incident report, the exact cause remains unknown.
📉 Impact on Businesses and Users
Given Cloudflare’s role in routing and securing a massive portion of the internet, today’s outage affects:
For Individuals
- WARP connectivity failures (London)
- Slow or broken websites
- Unreliable application access
For Businesses
- Checkout failures
- API-based services down
- Authentication issues
- Dashboard unavailability
- Failed deployments
- Customer support overload
For Developers
- CI/CD pipeline failures
- Worker/Pages deployment issues
- Delayed DNS propagation
This downtime is particularly disruptive for companies relying on Cloudflare’s Zero Trust and WARP services for remote connectivity.
🔧 Cloudflare’s Current Priorities
Based on the updates and the disabling of WARP in London, Cloudflare is likely:
- Isolating unstable PoPs
- Rolling back recent global configurations
- Restarting and stabilizing internal service clusters
- Re-routing global traffic
- Deploying emergency patches
- Working with regional teams for faster remediation
A coordinated global incident response team is likely mobilized.
📢 What Customers Should Do Right Now
- Avoid large DNS or firewall changes
- Prepare for intermittent failures
- Notify internal teams (IT, cybersecurity, and engineering)
- Use alternative VPN or routing for London-based users
- Follow Cloudflare’s official status updates
- Implement fallback routing where available
Cloudflare may take additional remediation actions that temporarily disable further services or regions.
📌 Conclusion
Cloudflare’s ongoing global network outage has intensified, with the company taking the unusual step of disabling WARP connectivity in London as part of remediation efforts. Despite partial recovery earlier in the day, multiple updates show that Cloudflare engineers are still investigating the underlying issue and working to stabilize the network.
This incident underscores the complexity of Cloudflare’s global infrastructure—and how quickly internal issues can cascade across the internet.
More updates from Cloudflare are expected shortly, and a full post-incident report will likely follow once services are restored.