Cloudflare Global Network Outage — Full Technical Analysis Report
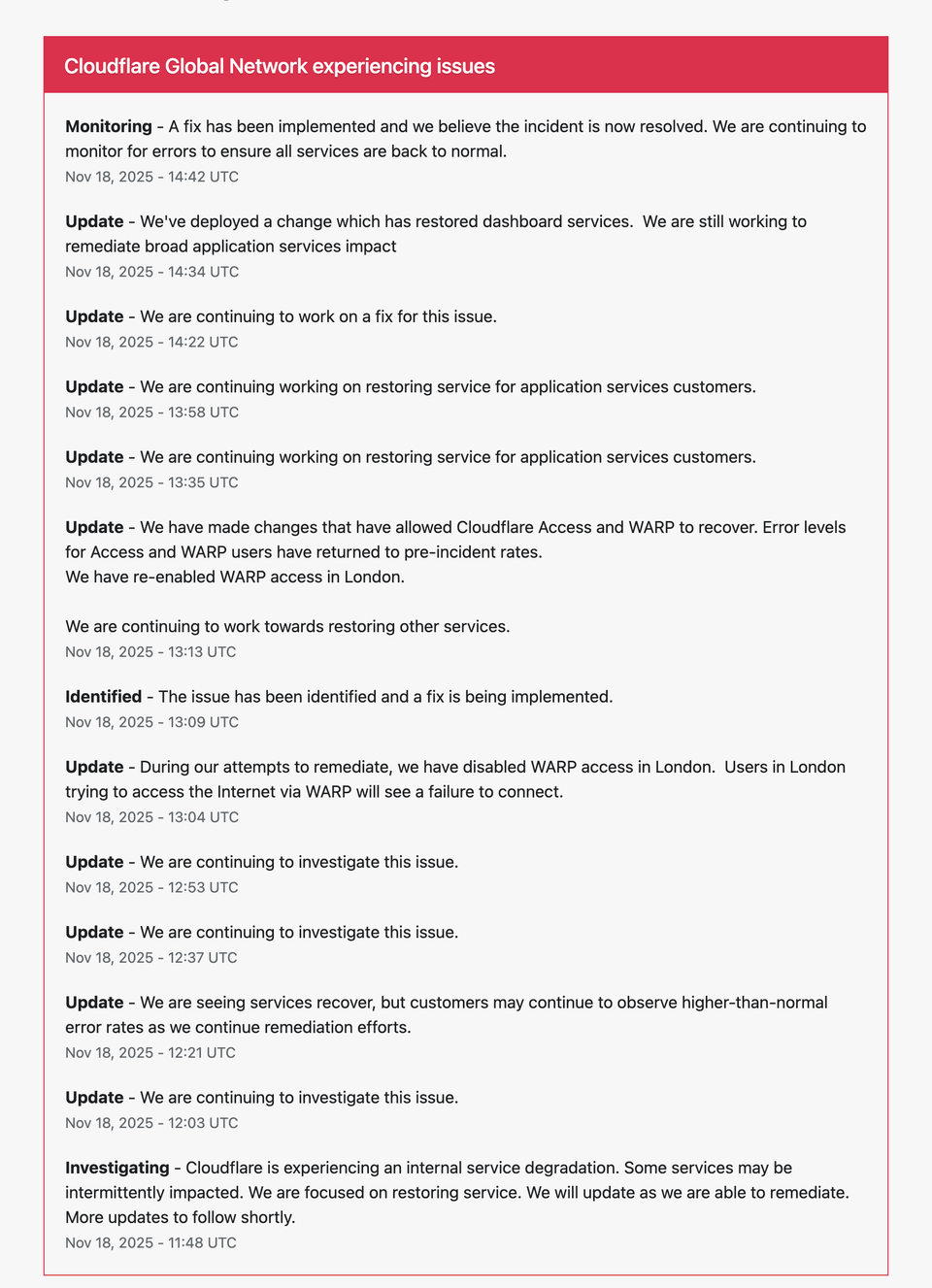
Date: November 18, 2025
Status: Monitoring — Incident believed resolved at 14:42 UTC.
1. Executive Summary
On November 18, 2025, Cloudflare experienced a significant global service disruption affecting core infrastructure layers including routing, dashboard access, WARP connectivity, Zero Trust authentication, CDN traffic, and application-level services.
The outage lasted approximately 3 hours and required multiple remediation actions, including temporarily disabling WARP in London to isolate unstable regional traffic.
Cloudflare has since restored most services and is actively monitoring for lingering errors. Dashboard services have been re-enabled, Access and WARP have returned to pre-incident error levels, and the company has identified and implemented a fix for the core issue.
This event demonstrates the deep dependency of the internet on Cloudflare and highlights the complexities of resolving internal systemic failures at global scale.
2. Complete Timeline of Events (UTC)
11:48 — Initial Incident Identified (Internal Degradation)
Cloudflare reports internal service degradation.
Impacted services included:
- Routing and CDN
- Dashboard & API
- WARP
- Access (Zero Trust)
- Workers & Pages deployments
12:03 — Continuing Investigation
No resolution yet. Engineers were analyzing fault domains.
12:21 — Partial Recovery Observed
Some services began to stabilize.
However, error rates remained higher than normal.
12:37 & 12:53 — Ongoing Investigation
Cloudflare still unable to identify the root cause.
Global instability persisted.
13:04 — WARP Disabled in London (Critical Step)
Cloudflare disables WARP regionally to prevent cascading network failures.
Users in London unable to connect using WARP.
This is a rare and high-severity mitigation tactic, indicating London PoP instability likely contributed to the issue.
13:09 — Issue Identified, Fix Being Implemented
This marks the turning point.
Cloudflare isolates the root cause and begins pushing a fix across the network.
13:13 — Access & WARP Fully Restored
Cloudflare reports:
- Access error rates back to pre-incident levels
- WARP restored
- WARP London re-enabled
- Continued work on other services
This suggests the fix successfully stabilized the Zero Trust environment and secure tunneling traffic.
13:35 & 13:58 — Ongoing Restoration of Application Services
Cloudflare engineers focus on:
- Application-layer remediation
- CDN traffic normalization
- Worker/Page service recovery
Residual problems likely remained in config propagation and cache invalidation.
14:34 — Dashboard Services Restored
Cloudflare deploys a fix enabling dashboard access globally.
This is typically one of the last services to recover due to dependency on internal APIs.
14:42 — Monitoring (Incident Believed Resolved)
Cloudflare announces:
“A fix has been implemented and we believe the incident is now resolved.”
Engineers continue monitoring for anomalies to ensure full stability.
3. Impact Assessment
Impacted Cloudflare Products
- CDN & Edge Routing → 500/502/503 errors
- DNS Resolution → intermittent failures
- Cloudflare Dashboard → inaccessible for ~2 hours
- Cloudflare API → automation failures, CI/CD errors
- Cloudflare Access (Zero Trust) → login failures, internal apps unreachable
- Cloudflare WARP → disabled in London, global degradation
- Workers & Pages → deployment failures
- Application Services → instability in global PoPs
Global Business Impact
Companies relying on Cloudflare experienced:
- Broken authentication flows
- Checkout failures & revenue loss
- Slowed or blocked API traffic
- Downtime for internal applications
- Remote employees locked out of secured networks
- Deployment delays across dev teams
Given Cloudflare protects & routes a massive share of global internet traffic, the incident had cascading global effects within minutes.
4. Technical Root Cause (Likely Scenarios)
Cloudflare has not yet provided a detailed root-cause report, but based on behavior and historical patterns, the following are highly probable:
Scenario A — Faulty Global Configuration Push (Most Likely)
Symptoms consistent with:
- Sudden burst of 500 errors
- Dashboard/API outage
- WARP issues
- Regional PoP instability
Possible faulty component areas:
- WAF rules
- Internal routing rules
- Reverse proxy logic
- Rate limiting engine
- Authentication microservices
Cloudflare has experienced similar outages from WAF misconfigurations (e.g., 2020 incident).
Scenario B — Internal Microservice Failure
If a core internal control-plane service failed or miscommunicated:
- Config propagation would break
- PoPs become unsynchronized
- Zero Trust & WARP services degrade
- Dashboard & API calls fail
This aligns with Access, WARP, and Dashboard all breaking simultaneously.
Scenario C — Anycast/BGP Instability in London PoP
Disabling WARP in London hints at:
- A London PoP routing loop
- Corrupted config in that region
- Divergent Anycast behavior
- Localized packet drops or congestion
London has historically been one of the busiest Cloudflare PoPs globally.
Scenario D — Cascading Internal System Overload
Initial degradation could have triggered:
- Restart storms
- Cache poisoning
- Queue buildup
- Authentication backlog
Less likely but possible.
5. How Cloudflare Resolved the Incident
- Isolated unstable components
- Disabled WARP London
- Reduced load on affected systems
- Stopped propagation of faulty configurations
- Identified root cause
- Actionable fix began at 13:09 UTC
- Re-enabled Zero Trust & WARP
- Access and WARP restored by 13:13
- Restored application services
- Gradual PoP-by-PoP stabilization
- Dashboard services restored
- Fix deployed at 14:34
- Full resolution & monitoring
- Declared stable at 14:42 UTC
6. Lessons Learned
1. Single-provider dependency is a systemic risk
When Cloudflare breaks, the internet breaks.
2. Zero Trust adds another dependency layer
If your identity gateway is down, your workforce is locked out.
3. Global configuration pushes are powerful—and dangerous
One mistake can propagate worldwide instantly.
4. Regional isolation is an effective emergency tool
Disabling WARP in London prevented global cascading failures.
5. Observability must extend beyond your infrastructure
Many companies detected the outage only via:
- user complaints
- CI/CD failures
- unresponsive dashboards
External dependency monitoring is critical.
6. Incident communication matters
Cloudflare provided rapid updates, reducing confusion for engineering teams.
7. Recommendations for Organizations
For Engineering & DevOps
- Implement DNS/CDN redundancy
- Design failover paths independent of Cloudflare
- Maintain alternative authentication routes
- Build rate limits & circuit breakers into your apps
For Security Teams
- Prepare Zero Trust bypass procedures
- Validate offline access methods
For Leadership
- Run tabletop exercises simulating provider outages
- Identify single points of dependency across architecture
- Document Cloudflare-dependency maps
8. Final Status
As of 14:42 UTC, Cloudflare reports:
✔ Fix implemented
✔ Access stabilized
✔ WARP restored everywhere
✔ Dashboard operational
✔ Application services recovering
✔ Monitoring ongoing
A full Cloudflare post-incident report is expected.