⚙️ AWS US-EAST-1 Outage: Full Recovery Underway After EC2 Network Root Cause Identified
Date: October 20, 2025
Region Affected: US-EAST-1 (N. Virginia)
Status: 🟡 Degraded – Recovery in Progress
🧭 Overview
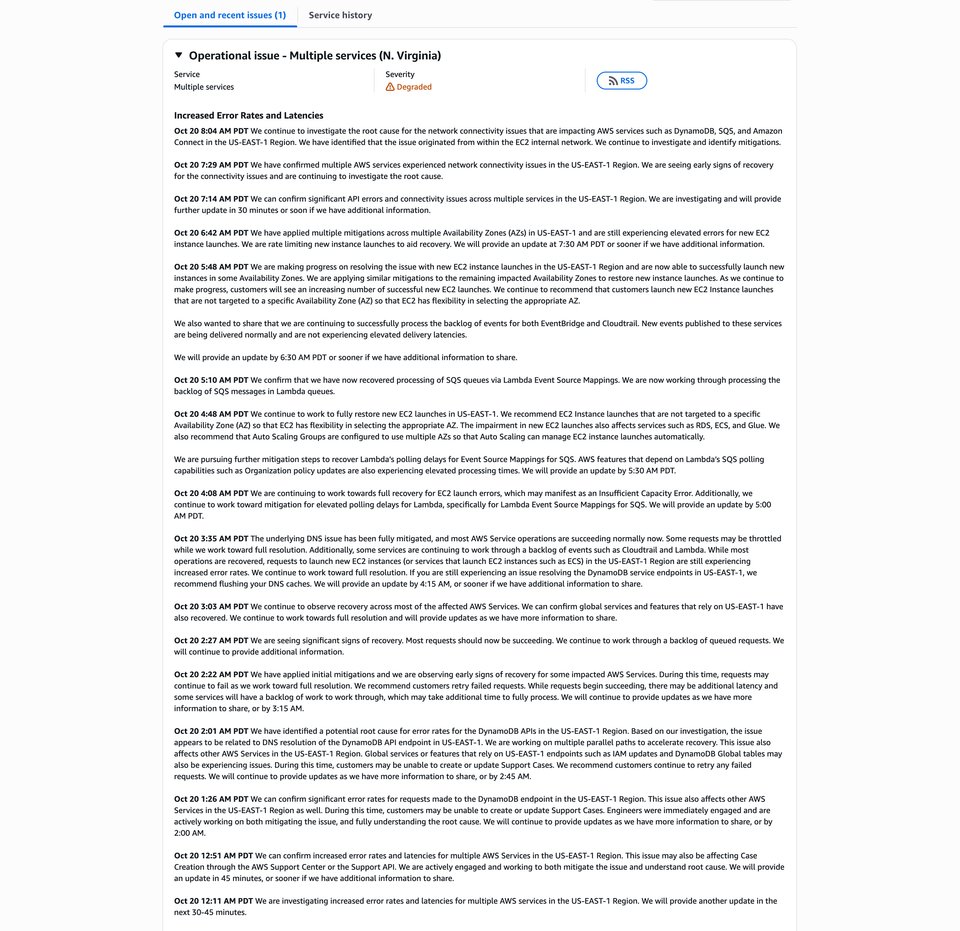
After nearly eight hours of widespread service disruptions, Amazon Web Services (AWS) has confirmed that the root cause of the connectivity issues in the US-EAST-1 (N. Virginia) region originated within the EC2 internal network infrastructure.
The outage affected more than 80 AWS services, including DynamoDB, Lambda, SQS, Amazon Connect, and EC2, causing API timeouts, failed launches, and elevated error rates across key workloads.
As of 8:04 AM PDT, AWS engineers report that mitigation efforts are ongoing, with many services showing early signs of recovery and API response times improving.
🕐 Incident Timeline
🕛 Oct 20, 12:11 AM PDT – Initial Investigation
AWS begins investigating increased error rates and latencies in the US-EAST-1 region.
Engineers report early service degradation across multiple systems.
🕧 Oct 20, 12:26 AM PDT – DynamoDB Disruption Confirmed
AWS confirms significant error rates for DynamoDB API requests.
Support case creation and several backend APIs also experience issues.
🕐 Oct 20, 2:01 AM PDT – Root Cause Identified: DNS Resolution Issue
The outage is traced to a DNS resolution problem affecting the DynamoDB API endpoint.
This leads to a cascading impact on global services using US-EAST-1 infrastructure.
🕓 Oct 20, 3:35 AM PDT – DNS Fully Mitigated
The underlying DNS issue is fully mitigated.
However, new EC2 instance launches remain problematic, and Lambda queues show delays.
🕔 Oct 20, 4:48 AM PDT – Focus on EC2 and Lambda
AWS engineers focus on restoring EC2 launches and Lambda SQS Event Source Mappings.
Rate-limiting is applied to control instance recovery.
🕠 Oct 20, 5:10 AM PDT – Lambda Fully Recovered
AWS confirms that Lambda and SQS message polling have fully recovered.
Backlogged messages are being processed.
🕕 Oct 20, 5:48–6:42 AM PDT – Partial EC2 Recovery
New EC2 instances begin launching in some Availability Zones (AZs).
Engineers apply mitigations and rate limits to maintain stability.
🕖 Oct 20, 7:14–7:29 AM PDT – Network Connectivity Issues Detected
AWS confirms API errors and connectivity failures across multiple services in US-EAST-1.
By 7:29 AM PDT, early signs of recovery are observed as traffic stabilizes.
🕗 Oct 20, 8:04 AM PDT – Root Cause Found in EC2 Internal Network
AWS officially identifies the EC2 internal network as the source of the ongoing connectivity problems.
The issue directly impacted DynamoDB, SQS, and Amazon Connect, with engineers now applying targeted mitigations.
⚙️ Affected AWS Services
The outage affected 82 AWS services, including:
- Compute & Networking: EC2, ECS, EKS, Lambda, VPC, Transit Gateway
- Databases: DynamoDB, RDS, Aurora, DocumentDB
- Storage: S3, FSx, EFS, Storage Gateway, DataSync
- Security & Identity: IAM, STS, Secrets Manager, Private CA
- Messaging: SQS, SNS, SES
- Analytics & AI: SageMaker, Glue, Kinesis, Athena
- Monitoring & Management: CloudWatch, CloudTrail, Systems Manager
- Developer Tools: CloudFormation, CodeBuild, CodePipeline
Because most AWS APIs rely on internal EC2 network routes and regional DNS endpoints, the impact propagated widely even though the original failure point was internal.
🧠 Technical Deep Dive: How the EC2 Internal Network Caused a Chain Reaction
The EC2 internal network is the foundational layer supporting AWS communication between services.
When a core network component within this layer fails, API calls between dependent services begin to time out or drop.
Key failure impacts:
- DynamoDB API endpoints – unreachable from internal service calls.
- SQS queues – delayed message polling and Lambda triggers.
- Amazon Connect – degraded customer communication sessions.
- CloudWatch – delayed or incomplete monitoring data.
- IAM and STS – temporary authentication slowdowns.
Even after DNS recovery, these connectivity issues continued because the EC2 internal service mesh (responsible for routing API traffic) experienced packet loss and internal link congestion.
AWS’s mitigation involved:
- Rerouting traffic between Availability Zones.
- Restarting EC2 internal gateway nodes.
- Rate-limiting instance creation to control traffic spikes.
- Incrementally restoring API gateway endpoints.
🧩 Why the EC2 Internal Network Is So Critical
In AWS, EC2 doesn’t just host virtual machines — it also provides the infrastructure backbone for many managed services.
When EC2’s internal control plane is disrupted:
- Auto Scaling can’t spin up or down instances.
- Elastic Load Balancers lose backend connectivity.
- APIs that depend on EC2-based networking (like Lambda and SQS) face internal timeouts.
Essentially, EC2 acts as the cloud’s circulatory system, and when it’s impaired, nearly every dependent service feels the effect.
🔍 AWS Engineering Response
AWS engineers executed the following mitigation phases:
- Isolation of Impacted Subnets
Internal EC2 routing layers were segmented to prevent propagation of network errors. - Progressive Traffic Rebalancing
Service traffic was redistributed across healthy Availability Zones. - Targeted API Gateway Recovery
Prioritized restoration of DynamoDB, Lambda, and SQS endpoints. - Monitoring and Validation
Continuous metrics evaluation via CloudWatch and Route 53 health checks.
AWS confirmed ongoing internal monitoring to validate recovery stability.
💡 Lessons for DevOps and Cloud Architects
This outage underscores several best practices for resilient cloud system design:
- Always assume regional dependencies exist – Even global services may rely on single-region backbones.
- Implement DNS caching and fallback logic – Prevent cascading failures when endpoints are temporarily unreachable.
- Design for API failure – Build retry logic and circuit breakers.
- Use multi-region replication – Spread mission-critical workloads beyond US-EAST-1.
- Leverage status APIs and health dashboards – Monitor AWS events and automate alerts.
📈 Recovery Summary (as of 8:04 AM PDT)
| Category | Status | Notes |
|---|---|---|
| DNS / DynamoDB | ✅ Stable | Fully recovered and operational |
| EC2 Internal Network | ⚙️ Degraded | Root cause identified, mitigations ongoing |
| Lambda / SQS | ✅ Recovered | Processing backlog |
| Amazon Connect | ⚠️ Partial Impact | Latency due to internal connectivity |
| CloudWatch / IAM | ✅ Operational | Monitoring normal |
| New EC2 Launches | 🔄 Rate-Limited | Gradual restoration continues |
🧭 Final Thoughts
The AWS US-EAST-1 outage once again highlights how complex and interconnected cloud ecosystems are.
While AWS maintains an extraordinary uptime record, this incident demonstrates that even small internal networking anomalies can ripple through dozens of dependent services.
Thanks to rapid engineering response and transparent updates, AWS is on track for full recovery, but the lessons on redundancy, dependency management, and architectural resilience remain essential for all DevOps teams.
📘 Source: AWS Service Health Dashboard – US-EAST-1 Incident
🔗 Full live timeline: Dargslan Publishing AWS Outage Report
If you’d like to learn more about cloud reliability, API networking, and AWS architecture,
visit 👉 dargslan.com — your trusted hub for IT insights and infrastructure learning.