Cloudflare Global Network Outage: Issue Identified, Fix Being Implemented
Cloudflare has announced a major breakthrough in the ongoing global outage affecting millions of websites, applications, APIs, and security services. As of 13:09 UTC, the company has officially identified the root cause of the disruption and is now actively implementing a fix.
This marks the first definitive progress since the incident began earlier in the day, when widespread 500 errors, Dashboard/API failures, and internal service degradation caused severe instability across Cloudflare’s global network.
🟥 13:09 UTC — Issue Identified
Cloudflare’s latest update states:
“Identified – The issue has been identified and a fix is being implemented.”
After hours of investigation and partial recovery attempts, Cloudflare has now isolated the underlying cause of the outage. While full details have not yet been made public, this update indicates that Cloudflare engineers have moved from diagnosis to remediation.
A fix is currently being deployed across the global infrastructure.
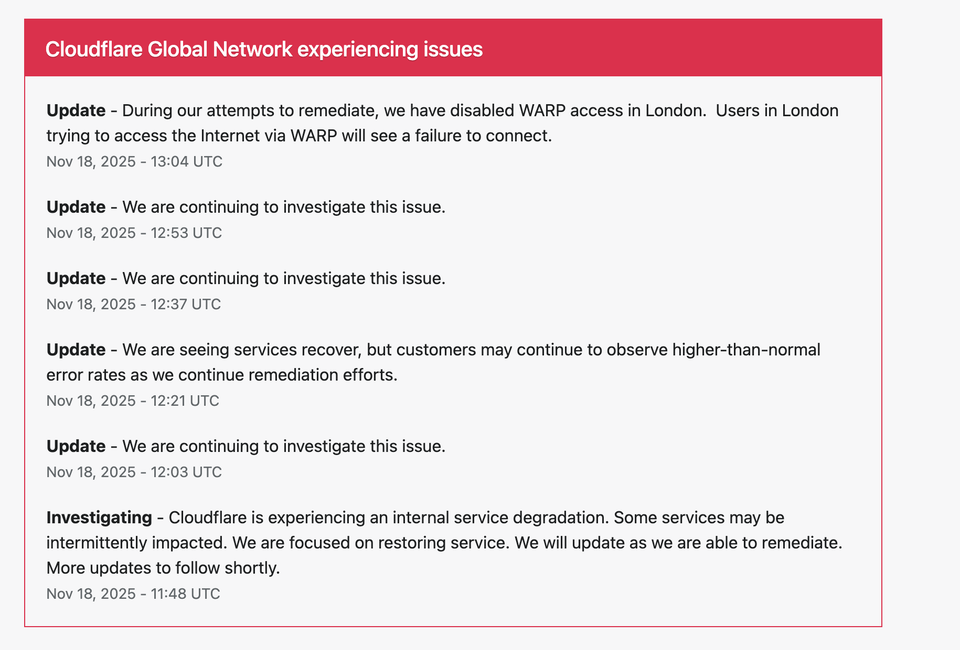
🟧 13:04 UTC — WARP Disabled in London
Just minutes before identifying the issue, Cloudflare took the significant step of disabling WARP connectivity in London:
“We have disabled WARP access in London. Users in London trying to access the Internet via WARP will see a failure to connect.”
This suggests that Cloudflare isolated or shut down regional traffic pathways to stabilize the larger network.
WARP users in London remain unable to connect until remediation completes.
🟧 12:53, 12:37 UTC — Continued Investigation
Cloudflare repeatedly confirmed:
“We are continuing to investigate this issue.”
These updates reflected ongoing instability and difficulty pinpointing a root cause.
🟧 12:21 UTC — Partial Recovery Noted
Earlier in the day, Cloudflare observed some recovery:
“We are seeing services recover, but customers may continue to observe higher-than-normal error rates.”
This partial recovery was temporary and incomplete.
🟥 11:48 UTC — Initial Incident Report
The incident began with Cloudflare reporting:
“Cloudflare is experiencing an internal service degradation. Some services may be intermittently impacted.”
This initial alert confirmed widespread issues across Cloudflare’s internal systems.
🌍 What Was Impacted?
Cloudflare’s disruption affected a wide range of services:
Global CDN & Web Traffic
- Widespread 500/502/503 errors
- Site loading failures
- High latency
Cloudflare Dashboard
- Login failures
- Unresponsive control panel
- Delayed analytics
Cloudflare API
- Failed integration requests
- Deployment errors
- Authentication failures
Zero Trust / Access
- Login interruptions
- Inconsistent policy enforcement
WARP
- Completely disabled in London
- Likely degraded elsewhere
Workers / Pages
- Deployment errors
- Delayed script execution
Because Cloudflare handles traffic for a significant portion of the global internet, even partial instability has wide-reaching consequences.
⚠️ Why This Outage Was Severe
Several factors made this outage unusually impactful:
1. Multi-layer internal failure
Cloudflare described the issue as internal service degradation, indicating multiple systems were affected at once.
2. Regional deactivation (London WARP)
Disabling WARP in a major city is a rare step for Cloudflare.
3. Prolonged investigation
It took nearly 90 minutes to identify the root cause.
4. Cascading global impact
With Cloudflare’s Anycast architecture, failures propagate worldwide almost instantly.
🔧 What Happens Next?
Since Cloudflare has moved to the fix implementation stage, we can expect:
➤ Gradual recovery across regions
Some PoPs may stabilize faster than others.
➤ Higher-than-normal error rates
These may persist until the fix fully propagates.
➤ Dashboard & API stability improvements
Administrative tools will likely recover last.
➤ WARP restoration (London)
Service will return once the regional pathways are stable.
➤ Further status updates
Cloudflare will publish more details as the fix rolls out.
A full technical postmortem is also expected after the incident concludes.
📌 Conclusion
Cloudflare’s global outage reached a turning point at 13:09 UTC, when the company confirmed that the root cause had been identified and that a fix was being deployed. This marks the first major step toward restoring full service after hours of instability affecting millions of users worldwide.
Although WARP remains disabled in London and some services are still degraded, Cloudflare is now actively implementing a solution. More updates are expected as remediation progresses.
This incident highlights the immense scale and complexity of Cloudflare’s global network—and the impact when one of its critical systems experiences internal failure.