Understanding SQL Joins: INNER, LEFT, RIGHT Explained
Sponsor message — This article is made possible by Dargslan.com, a publisher of practical, no-fluff IT & developer workbooks.
Why Dargslan.com?
If you prefer doing over endless theory, Dargslan’s titles are built for you. Every workbook focuses on skills you can apply the same day—server hardening, Linux one-liners, PowerShell for admins, Python automation, cloud basics, and more.
Database queries form the backbone of modern application development, yet many developers struggle with one of SQL's most fundamental concepts: joins. Whether you're building a customer management system, analyzing business data, or creating complex reports, understanding how to properly combine data from multiple tables can mean the difference between efficient, accurate queries and frustrating performance bottlenecks. The ability to retrieve related information across different database tables isn't just a technical skill—it's a critical competency that directly impacts application performance, data integrity, and your ability to extract meaningful insights from stored information.
At its core, a join operation allows you to combine rows from two or more tables based on related columns between them. This article explores the three most commonly used join types—INNER, LEFT, and RIGHT—examining not only their syntax and mechanics but also the practical scenarios where each excels. We'll look at real-world examples, common pitfalls, and the subtle differences that can dramatically affect your query results.
By the end of this exploration, you'll have a comprehensive understanding of when to use each join type, how they handle missing data differently, and practical strategies for optimizing join performance in production environments. You'll gain confidence in writing complex queries, troubleshooting unexpected results, and making informed decisions about database design that accommodate your application's specific data retrieval needs.
The Foundation: Understanding Table Relationships
Before diving into specific join types, it's essential to understand why joins exist in the first place. Relational databases organize information into separate tables to eliminate redundancy and maintain data integrity—a principle known as normalization. For instance, instead of storing customer details repeatedly with every order, you maintain a Customers table and an Orders table, linking them through a common identifier like customer_id. This approach reduces storage requirements and ensures that updating a customer's address happens in one place rather than across hundreds of order records.
The relationship between tables typically follows one of three patterns: one-to-one, one-to-many, or many-to-many. A one-to-many relationship is most common—one customer can have many orders, but each order belongs to exactly one customer. Understanding these relationships helps you determine which join type will produce the results you need. The join condition, typically specified in the ON clause, defines how rows from different tables relate to each other, usually through primary and foreign key relationships.
"The most critical aspect of writing effective joins is understanding your data model and the relationships between tables before you write a single line of SQL."
Key Components of Join Syntax
Every join operation contains several essential elements that work together to combine data. The SELECT clause determines which columns appear in your result set, the FROM clause specifies your primary table, the JOIN keyword identifies the table you're combining with, and the ON clause establishes the relationship between them. Additionally, you can include WHERE clauses to filter results, GROUP BY for aggregations, and ORDER BY to control result ordering. Understanding how these components interact is crucial because their order affects both query performance and result accuracy.
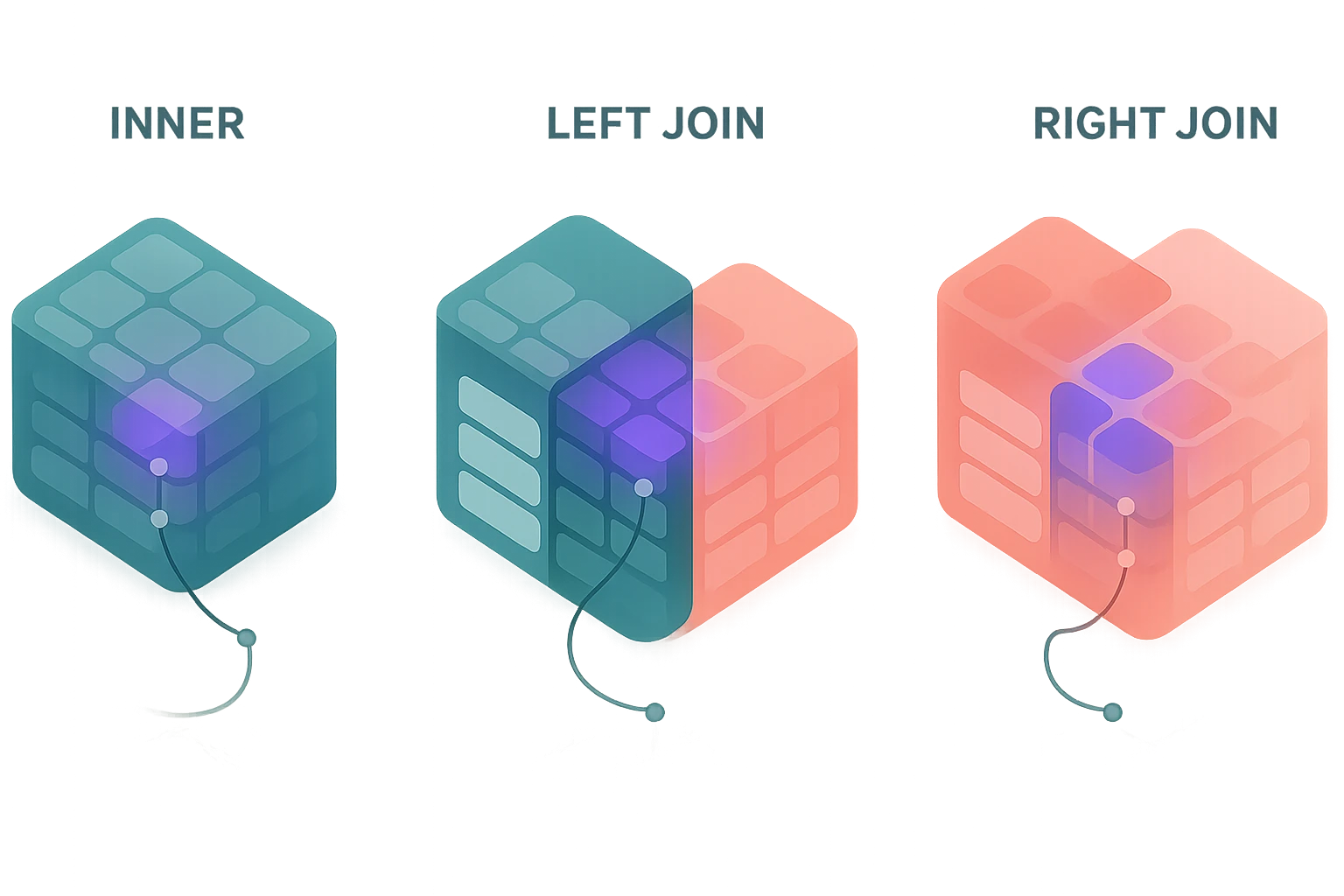
INNER JOIN: The Intersection Approach
The INNER JOIN returns only the rows where matching values exist in both tables. Think of it as finding the intersection in a Venn diagram—only records that satisfy the join condition in both tables appear in the result set. This makes INNER JOIN the most restrictive join type, but also the most commonly used because it ensures you're working with complete, related data. When you need to display orders along with customer information, an INNER JOIN guarantees that every row in your result has both valid order data and corresponding customer details.
| Characteristic | INNER JOIN Behavior | Practical Impact |
|---|---|---|
| Matching Requirement | Requires matching values in both tables | Excludes orphaned records automatically |
| NULL Handling | Excludes rows with NULL in join columns | May hide incomplete data relationships |
| Result Set Size | Smallest among join types | Better performance with large datasets |
| Use Case | When you need guaranteed related data | Order reports with customer details |
| Data Integrity | Ensures referential integrity in results | Prevents incomplete information display |
Practical INNER JOIN Examples
Consider a scenario where you're building a sales dashboard that displays order information alongside customer names. Your Orders table contains order_id, customer_id, order_date, and total_amount. Your Customers table has customer_id, customer_name, email, and phone. Using an INNER JOIN on customer_id ensures that only orders with valid customer records appear in your report. This is particularly valuable when data integrity isn't perfect—perhaps some old orders reference customers who've been deleted from the system. The INNER JOIN automatically filters these problematic records, showing only valid, complete information.
SELECT
o.order_id,
o.order_date,
o.total_amount,
c.customer_name,
c.email
FROM Orders o
INNER JOIN Customers c ON o.customer_id = c.customer_id
WHERE o.order_date >= '2024-01-01'
ORDER BY o.order_date DESC;This query retrieves orders from 2024 along with customer information, but only for orders that have corresponding customer records. If an order references a customer_id that doesn't exist in the Customers table, that order won't appear in the results. This behavior is exactly what you want when generating customer-facing reports, but it might hide data quality issues if you're trying to audit your database for orphaned records.
"INNER JOIN is your safeguard against displaying incomplete information, but it can also mask data quality problems by silently excluding problematic records."
Multiple Table INNER JOINs
Real-world applications often require joining more than two tables. Imagine adding product information to your order report. You might have an OrderItems table that connects orders to products, and a Products table with product details. You can chain multiple INNER JOINs together, with each subsequent join building on the previous result set. The order of joins can affect performance, so database query optimizers work to determine the most efficient execution path based on table sizes, indexes, and join conditions.
SELECT
o.order_id,
c.customer_name,
p.product_name,
oi.quantity,
oi.unit_price
FROM Orders o
INNER JOIN Customers c ON o.customer_id = c.customer_id
INNER JOIN OrderItems oi ON o.order_id = oi.order_id
INNER JOIN Products p ON oi.product_id = p.product_id
WHERE o.order_date BETWEEN '2024-01-01' AND '2024-12-31';This query demonstrates the cascading nature of INNER JOINs. Each join further restricts the result set, ensuring that only complete records—those with valid customers, order items, and product information—appear in the output. If any link in this chain breaks (a missing customer, an order with no items, or an item referencing a deleted product), the entire record disappears from the results.
LEFT JOIN: Preserving the Primary Table
The LEFT JOIN (also called LEFT OUTER JOIN) takes a different approach by returning all rows from the left table regardless of whether matching rows exist in the right table. When matches occur, you get the combined data just like an INNER JOIN. However, when no match exists, the query still returns the left table's row with NULL values for all columns from the right table. This asymmetric behavior makes LEFT JOIN invaluable when you need to preserve your primary dataset while optionally including related information.
The "left" designation refers to table position in your SQL statement—the table in the FROM clause is the left table, while the table in the JOIN clause is the right table. This distinction matters significantly because swapping table positions in a LEFT JOIN produces different results. Understanding this directionality is crucial for writing queries that return the data you actually need rather than an unexpected subset.
When LEFT JOIN Becomes Essential
📊 Reporting scenarios: Imagine generating a customer list showing total order values. Some customers might not have placed any orders yet. An INNER JOIN would exclude these customers entirely, giving you an incomplete view of your customer base. A LEFT JOIN includes all customers, showing NULL or zero for order totals where no orders exist.
📊 Data quality auditing: When investigating data integrity issues, LEFT JOIN helps identify orphaned or missing relationships. You can find customers without orders, products never purchased, or employees without assigned departments by checking for NULL values in the joined table's columns.
📊 Optional relationships: Not all relationships are mandatory. A user profile might optionally link to a profile picture. Using LEFT JOIN ensures all users appear in your query results regardless of whether they've uploaded a picture, with NULL values indicating missing pictures.
📊 Aggregation with completeness: When calculating statistics like average order value per customer, LEFT JOIN ensures customers without orders still appear with appropriate zero or NULL values rather than being excluded from your analysis entirely.
📊 Historical data preservation: When joining current data with historical records that might not exist for all entries, LEFT JOIN maintains the complete current dataset while adding historical context where available.
| Scenario | INNER JOIN Result | LEFT JOIN Result |
|---|---|---|
| Customer with 3 orders | 3 rows (one per order) | 3 rows (one per order) |
| Customer with 0 orders | 0 rows (customer excluded) | 1 row (customer included, order fields NULL) |
| Total customer count | Only customers with orders | All customers in database |
| Performance impact | Generally faster | Slightly slower due to NULL handling |
| Data completeness | Shows only related data | Shows all primary table data |
LEFT JOIN Syntax and Examples
The syntax for LEFT JOIN mirrors INNER JOIN with one keyword difference. Consider a query that lists all customers along with their order counts, including customers who haven't ordered anything. This is impossible with INNER JOIN because customers without orders would be excluded entirely.
SELECT
c.customer_id,
c.customer_name,
c.email,
COUNT(o.order_id) as order_count,
COALESCE(SUM(o.total_amount), 0) as total_spent
FROM Customers c
LEFT JOIN Orders o ON c.customer_id = o.customer_id
GROUP BY c.customer_id, c.customer_name, c.email
ORDER BY order_count DESC;This query returns every customer in your database. The COUNT function counts actual order_id values, returning 0 for customers without orders (since COUNT doesn't count NULL values). The COALESCE function handles the SUM of total_amount, converting NULL to 0 for customers without orders. Without LEFT JOIN, customers who never ordered would simply disappear from your results, giving you an inaccurate picture of your customer base.
"LEFT JOIN is the tool of choice when your primary concern is preserving the completeness of your main dataset while optionally enriching it with related information."
Identifying Missing Relationships with LEFT JOIN
One powerful application of LEFT JOIN is finding records that lack expected relationships. By checking for NULL values in the joined table's primary key, you can identify orphaned or incomplete data. This technique is invaluable for data quality monitoring and cleanup operations.
SELECT
c.customer_id,
c.customer_name,
c.registration_date
FROM Customers c
LEFT JOIN Orders o ON c.customer_id = o.customer_id
WHERE o.order_id IS NULL
AND c.registration_date < DATE_SUB(CURRENT_DATE, INTERVAL 90 DAY);This query identifies customers who registered more than 90 days ago but have never placed an order. The WHERE clause filters for NULL in order_id, which only occurs when no matching orders exist. This information might trigger marketing campaigns targeting inactive customers or help identify issues with the registration-to-purchase funnel.
RIGHT JOIN: The Mirror Image
RIGHT JOIN (or RIGHT OUTER JOIN) works exactly like LEFT JOIN but in reverse—it returns all rows from the right table (the one in the JOIN clause) regardless of matches in the left table (the one in the FROM clause). While functionally equivalent to swapping table positions and using LEFT JOIN, RIGHT JOIN can sometimes make queries more readable when the logical flow of your query emphasizes the joined table rather than the primary table.
In practice, RIGHT JOIN is used far less frequently than LEFT JOIN, primarily because most developers find it more intuitive to think of the FROM table as primary and the JOIN table as supplementary. Many coding standards and style guides actually discourage RIGHT JOIN usage, recommending that developers restructure queries to use LEFT JOIN instead. However, understanding RIGHT JOIN remains important for reading others' code and recognizing that it provides the same functionality as LEFT JOIN with reversed table positions.
"While RIGHT JOIN has its place, most experienced database developers prefer restructuring queries with LEFT JOIN for consistency and readability."
RIGHT JOIN Practical Application
Consider a scenario where you're analyzing product performance and want to list all products along with their sales data, including products that have never been sold. You might write this query with RIGHT JOIN if you're thinking primarily about the Products table:
SELECT
p.product_id,
p.product_name,
p.category,
COUNT(oi.order_item_id) as times_ordered,
COALESCE(SUM(oi.quantity), 0) as total_quantity_sold
FROM OrderItems oi
RIGHT JOIN Products p ON oi.product_id = p.product_id
GROUP BY p.product_id, p.product_name, p.category
HAVING times_ordered = 0;This query returns products that have never been ordered. However, most developers would find this more readable as a LEFT JOIN with swapped table positions:
SELECT
p.product_id,
p.product_name,
p.category,
COUNT(oi.order_item_id) as times_ordered,
COALESCE(SUM(oi.quantity), 0) as total_quantity_sold
FROM Products p
LEFT JOIN OrderItems oi ON p.product_id = oi.product_id
GROUP BY p.product_id, p.product_name, p.category
HAVING times_ordered = 0;Both queries produce identical results, but the LEFT JOIN version reads more naturally—starting with Products as the primary subject and adding OrderItems as supplementary information. This structural consistency makes code easier to maintain and reduces cognitive load when reading complex queries.
Performance Considerations and Optimization
Join performance can significantly impact application responsiveness, especially as data volumes grow. Several factors influence join efficiency, with indexing being the most critical. Indexes on join columns (typically foreign keys) allow the database engine to quickly locate matching rows rather than scanning entire tables. Without proper indexes, even simple joins can become prohibitively slow as tables grow beyond a few thousand rows.
The order of joins in multi-table queries can affect performance, though modern query optimizers usually handle this automatically. Generally, joining smaller result sets first reduces the amount of data processed in subsequent joins. For example, if you're filtering orders by date before joining with customers, applying that filter before the join reduces the number of customer lookups required. However, you should rely on your database's EXPLAIN or execution plan tools to understand actual performance rather than making assumptions.
Index Strategy for Optimal Join Performance
Creating indexes on foreign key columns is fundamental to join performance. When you join Orders to Customers on customer_id, an index on Orders.customer_id allows the database to quickly find all orders for each customer. Without this index, the database must scan the entire Orders table for each customer—an operation that becomes exponentially slower as data grows. Primary keys are automatically indexed, but foreign keys often require explicit index creation.
Composite indexes can further optimize queries that filter on multiple columns. If you frequently join Orders to Customers and filter by order_date, a composite index on (customer_id, order_date) might improve performance beyond separate indexes on each column. However, index maintenance has costs—every insert, update, or delete must update all relevant indexes, so excessive indexing can slow write operations. Balance is essential.
"The difference between a properly indexed join and an unindexed one can be the difference between a query that runs in milliseconds and one that times out after minutes."
Join Type Performance Characteristics
INNER JOIN typically performs best because it produces the smallest result set and allows the query optimizer the most flexibility in execution planning. The optimizer can choose which table to scan first based on statistics and filtering conditions. LEFT JOIN is generally slightly slower because it must preserve all rows from the left table and handle NULL values for non-matching rows. RIGHT JOIN has similar performance to LEFT JOIN but may confuse the optimizer in some database systems if used inconsistently.
When joining multiple tables, the number of rows returned at each step significantly affects overall performance. A join that produces millions of intermediate rows before filtering can be dramatically slower than one that filters early. Using WHERE clauses to reduce row counts before joins, when logically appropriate, often improves performance. However, be careful—filtering on the joined table's columns in a WHERE clause can effectively convert a LEFT JOIN into an INNER JOIN by excluding rows where those columns are NULL.
Common Pitfalls and How to Avoid Them
Even experienced developers encounter join-related issues that produce unexpected results or poor performance. Understanding these common mistakes helps you write more reliable queries and troubleshoot problems more effectively when they arise.
The Cartesian Product Trap
Forgetting or incorrectly specifying the join condition creates a cartesian product—every row from the first table combined with every row from the second table. If you have 1,000 customers and 10,000 orders, a missing join condition produces 10 million rows instead of the expected 10,000. This mistake is surprisingly easy to make when joining multiple tables, especially if you forget one ON clause in a chain of joins. The result is usually immediately obvious due to the enormous row count, but it can cause serious performance problems or even crash applications.
Filtering Confusion with LEFT JOIN
A subtle but critical mistake involves filtering on columns from the right table in a LEFT JOIN's WHERE clause. Consider this query intended to find customers and their recent orders:
SELECT c.customer_name, o.order_date, o.total_amount
FROM Customers c
LEFT JOIN Orders o ON c.customer_id = o.customer_id
WHERE o.order_date >= '2024-01-01';This query looks correct but actually behaves like an INNER JOIN. The WHERE clause filters out rows where order_date is NULL, which includes all customers without orders. To preserve the LEFT JOIN behavior while filtering orders, move the date condition into the ON clause or use a subquery. The corrected version looks like this:
SELECT c.customer_name, o.order_date, o.total_amount
FROM Customers c
LEFT JOIN Orders o ON c.customer_id = o.customer_id
AND o.order_date >= '2024-01-01';Now the date filter applies during the join operation, preserving customers without recent orders in the result set with NULL values for order columns.
"Placing filters on the joined table in the WHERE clause is one of the most common ways to accidentally convert a LEFT JOIN into an INNER JOIN."
Ambiguous Column References
When joining tables that have identically named columns, you must qualify column references with table names or aliases. Failing to do so results in ambiguous column errors. Even when column names are unique, using table aliases improves query readability and maintainability. Consistent aliasing conventions—like using the first letter of each table name—make complex queries easier to understand at a glance.
NULL Handling Oversights
NULL values behave differently than you might expect in join conditions and comparisons. A join condition like ON t1.column = t2.column doesn't match rows where either column is NULL because NULL doesn't equal NULL in SQL logic. If your data legitimately contains NULLs in join columns, you may need additional logic using IS NULL checks or COALESCE functions to handle these cases appropriately. Similarly, aggregate functions like COUNT, SUM, and AVG handle NULLs differently, which can produce unexpected results if you're not careful.
Advanced Join Techniques
Beyond basic join operations, several advanced techniques solve specific data retrieval challenges. These patterns are invaluable for complex reporting, data analysis, and application development scenarios.
Self Joins for Hierarchical Data
A self join connects a table to itself, useful for hierarchical relationships like employee-manager structures or category-subcategory arrangements. You treat the same table as two separate entities using different aliases. For example, finding all employees and their managers:
SELECT
e.employee_name as employee,
m.employee_name as manager,
e.department
FROM Employees e
LEFT JOIN Employees m ON e.manager_id = m.employee_id
ORDER BY e.department, e.employee_name;The LEFT JOIN ensures that top-level employees (those without managers) still appear in the results with NULL in the manager column. This technique extends to any scenario where records in a table relate to other records in the same table.
Finding Unmatched Records
LEFT JOIN combined with NULL checking efficiently identifies records in one table that lack corresponding records in another. This pattern is essential for data quality monitoring, identifying incomplete relationships, or finding gaps in your data. The technique works by performing a LEFT JOIN and then filtering for NULL values in the joined table's primary key.
Conditional Joins with Multiple Criteria
Join conditions aren't limited to simple equality checks. You can include multiple conditions, range comparisons, and complex logical expressions in the ON clause. For instance, joining orders to promotions based on both customer type and order date:
SELECT
o.order_id,
o.order_date,
o.total_amount,
p.promotion_name,
p.discount_percentage
FROM Orders o
LEFT JOIN Promotions p ON o.customer_type = p.eligible_customer_type
AND o.order_date BETWEEN p.start_date AND p.end_date
AND o.total_amount >= p.minimum_order_value;This query matches orders with applicable promotions based on multiple criteria. Orders that don't match any promotion still appear with NULL promotion values, allowing you to identify orders that didn't benefit from promotional discounts.
Choosing the Right Join Type
Selecting the appropriate join type depends on your specific requirements and the questions you're trying to answer with your data. The decision process should consider whether you need all records from one or both tables, how you want to handle missing relationships, and what your result set should look like.
Use INNER JOIN when you need only records that have valid relationships in both tables. This is appropriate for transactional queries where incomplete data shouldn't appear, such as displaying order details with customer information where both must exist. INNER JOIN is also the default choice for better performance when you know all records should have matching relationships.
Choose LEFT JOIN when you need all records from your primary table regardless of whether related records exist in the secondary table. This is essential for comprehensive reporting, data quality audits, or scenarios where relationships are optional. LEFT JOIN is also crucial when calculating statistics that should include zero values rather than excluding records entirely.
RIGHT JOIN serves the same purpose as LEFT JOIN but with reversed table emphasis. Unless your organization's coding standards specifically require it for certain scenarios, you can typically restructure queries to use LEFT JOIN instead, which most developers find more intuitive and consistent.
Real-World Application Scenarios
Understanding join theory is important, but seeing how these concepts apply to actual business problems helps cement your understanding and reveals the practical value of mastering join operations.
E-commerce Order Analysis
An e-commerce platform needs to generate a comprehensive sales report showing all products, their categories, total quantities sold, and revenue generated. Products that haven't sold yet should still appear with zero values. This requires LEFT JOIN to preserve all products:
SELECT
p.product_id,
p.product_name,
c.category_name,
COALESCE(COUNT(DISTINCT o.order_id), 0) as order_count,
COALESCE(SUM(oi.quantity), 0) as total_quantity_sold,
COALESCE(SUM(oi.quantity * oi.unit_price), 0) as total_revenue
FROM Products p
INNER JOIN Categories c ON p.category_id = c.category_id
LEFT JOIN OrderItems oi ON p.product_id = oi.product_id
LEFT JOIN Orders o ON oi.order_id = o.order_id
AND o.order_status = 'completed'
GROUP BY p.product_id, p.product_name, c.category_name
ORDER BY total_revenue DESC;This query uses INNER JOIN for the category relationship because every product must have a category, but LEFT JOIN for order items and orders to include products that haven't been purchased. The COALESCE functions ensure zero values appear instead of NULL for products without sales.
Customer Segmentation for Marketing
A marketing team wants to segment customers based on their purchase history, including customers who registered but never purchased. The analysis requires customer information, total purchase amounts, order frequency, and last purchase date. LEFT JOIN ensures all customers appear in the segmentation:
SELECT
c.customer_id,
c.customer_name,
c.email,
c.registration_date,
COUNT(o.order_id) as order_count,
COALESCE(SUM(o.total_amount), 0) as lifetime_value,
MAX(o.order_date) as last_purchase_date,
DATEDIFF(CURRENT_DATE, MAX(o.order_date)) as days_since_last_purchase,
CASE
WHEN COUNT(o.order_id) = 0 THEN 'Never Purchased'
WHEN DATEDIFF(CURRENT_DATE, MAX(o.order_date)) > 180 THEN 'Inactive'
WHEN DATEDIFF(CURRENT_DATE, MAX(o.order_date)) > 90 THEN 'At Risk'
ELSE 'Active'
END as customer_segment
FROM Customers c
LEFT JOIN Orders o ON c.customer_id = o.customer_id
GROUP BY c.customer_id, c.customer_name, c.email, c.registration_date
ORDER BY lifetime_value DESC;This segmentation query categorizes every customer in the database, including those who never made a purchase, enabling targeted marketing campaigns for each segment.
"The ability to include or exclude records based on relationship existence is what makes join operations so powerful for business intelligence and reporting."
Inventory Management and Supplier Tracking
An inventory system needs to track products, their current stock levels, and supplier information, including identifying products that need reordering and those without assigned suppliers. This scenario requires multiple join types to create a comprehensive view:
SELECT
p.product_id,
p.product_name,
i.quantity_on_hand,
i.reorder_level,
s.supplier_name,
s.contact_email,
CASE
WHEN s.supplier_id IS NULL THEN 'No Supplier Assigned'
WHEN i.quantity_on_hand <= i.reorder_level THEN 'Reorder Needed'
ELSE 'Stock OK'
END as inventory_status
FROM Products p
LEFT JOIN Inventory i ON p.product_id = i.product_id
LEFT JOIN Suppliers s ON p.supplier_id = s.supplier_id
WHERE i.quantity_on_hand <= i.reorder_level
OR s.supplier_id IS NULL
ORDER BY
CASE
WHEN s.supplier_id IS NULL THEN 1
WHEN i.quantity_on_hand <= i.reorder_level THEN 2
ELSE 3
END,
p.product_name;This query identifies products requiring attention—either they need reordering or they lack supplier information. The LEFT JOINs ensure all products appear even if inventory or supplier data is missing, which is crucial for identifying data gaps that require correction.
Testing and Validating Join Results
Ensuring your join queries return accurate, expected results requires systematic testing and validation. Several techniques help verify that your joins are working correctly and producing the data you need.
Start by testing with small, known datasets where you can manually verify results. Create test tables with a handful of records covering different scenarios: matching records, non-matching records, NULL values, and edge cases. Run your join query and compare the results with what you expect to see. This approach helps you catch logical errors before deploying queries against production data.
Count validation is essential, especially when using LEFT JOIN. Separately count rows in your primary table and compare with your join result count. For a LEFT JOIN, the result should never have fewer rows than the left table (though it might have more if the right table has multiple matching rows). For INNER JOIN, the result count should be less than or equal to both input tables. Unexpected counts often indicate missing join conditions or incorrect join types.
Check for NULL values in joined columns to verify join behavior. In a LEFT JOIN result, NULL values in right-table columns indicate rows from the left table without matches. If you're seeing NULLs when you expected data, investigate whether your join condition is correct or whether the expected relationships actually exist in your data. Conversely, if you're using LEFT JOIN specifically to find unmatched records and you're not seeing any NULLs, verify that your join condition isn't inadvertently matching everything.
Use aggregate functions to validate business logic. If you're joining orders to customers, sum the order totals and verify that the result matches your expected revenue figures. Discrepancies might indicate duplicate rows from incorrect join conditions or missing data from overly restrictive joins. Cross-reference your query results with known totals from other reports or system dashboards.
How do I decide between INNER JOIN and LEFT JOIN?
Choose INNER JOIN when you need only records with valid relationships in both tables, such as orders with customer details where both must exist. Use LEFT JOIN when you need all records from the primary table regardless of whether matching records exist in the secondary table, like listing all customers including those without orders. Consider whether excluding records without matches would give you incomplete or misleading information—if so, LEFT JOIN is appropriate.
Why does my LEFT JOIN seem to work like an INNER JOIN?
This usually happens when you filter on columns from the right table in the WHERE clause. Filtering for specific values in right-table columns automatically excludes rows where those columns are NULL (which occurs for unmatched left-table rows). To preserve LEFT JOIN behavior while filtering, move the condition into the ON clause or explicitly allow NULL values in your WHERE clause using OR IS NULL conditions.
Can joins cause duplicate rows in my results?
Yes, joins can produce duplicate rows when the right table has multiple matching rows for a single left-table row. For example, joining customers to orders produces one result row per order, so a customer with five orders appears five times. This is expected behavior for detail-level queries but can cause problems in aggregations if not handled properly with GROUP BY clauses. Use DISTINCT or appropriate grouping to eliminate unwanted duplicates.
How do indexes improve join performance?
Indexes on join columns allow the database to quickly locate matching rows instead of scanning entire tables. Without an index on the foreign key column, the database must examine every row in the table for each join operation, which becomes exponentially slower as data grows. Creating indexes on columns used in join conditions—typically foreign keys—can improve join performance by orders of magnitude, especially with large tables.
What's the difference between LEFT JOIN and LEFT OUTER JOIN?
There is no difference—LEFT JOIN and LEFT OUTER JOIN are identical operations with different syntax. The OUTER keyword is optional and purely stylistic. Most developers use the shorter LEFT JOIN syntax, but some coding standards require the explicit OUTER keyword for clarity. The same applies to RIGHT JOIN and RIGHT OUTER JOIN. Choose one style and use it consistently throughout your codebase.
Should I ever use RIGHT JOIN instead of LEFT JOIN?
RIGHT JOIN is functionally equivalent to swapping table positions and using LEFT JOIN, so it's rarely necessary. Most developers and coding standards prefer LEFT JOIN for consistency and readability since it's more intuitive to think of the FROM table as primary. However, RIGHT JOIN can occasionally make queries more readable when the logical emphasis is on the joined table rather than the primary table. If your team's style guide doesn't prohibit it, use whichever makes your specific query clearer.